import gym
import matplotlib
import numpy as np
import sys
from collections import defaultdict
import pprint as pp
from matplotlib import pyplot as plt
%matplotlib inline
import itertools
from matplotlib import cm, colors1. Introduction
In a Markov Decision Process (Figure 1) the agent and environment interacts continuously.

More details are available in Reinforcement Learning: An Introduction by Sutton and Barto.
The dynamics of the MDP is given by \[ \begin{aligned} p(s',r|s,a) &= Pr\{ S_{t+1}=s',R_{t+1}=r | S_t=s,A_t=a \} \\ \end{aligned} \]
The policy of an agent is a mapping from the current state of the environment to an action that the agent needs to take in this state. Formally, a policy is given by \[ \begin{aligned} \pi(a|s) &= Pr\{A_t=a|S_t=s\} \end{aligned} \]
The discounted return is given by \[ \begin{aligned} G_t &= R_{t+1} + \gamma R_{t+2} + \gamma ^2 R_{t+3} + ... + R_T \\ &= \sum_{k=0}^\infty \gamma ^k R_{t+1+k} \end{aligned} \] where \(\gamma\) is the discount factor and \(R\) is the reward.
Most reinforcement learning algorithms involve the estimation of value functions - in our present case, the action-value function. The action-value function maps each state-action pair to a measure of “how good it is to be in that state-action” in terms of expected rewards. Formally, the action-value function, under policy \(\pi\) is given by \[ \begin{aligned} q_\pi(s,a) &= \mathbb{E}_\pi[G_t|S_t=s, A_t=a] \end{aligned} \]
The Temporal Difference (TD) algorithm discussed in this post will numerically estimate \(q_\pi(s,a)\).
2. Environment
Figure 2 shows the environment we will use in this series: The Windy Gridworld:

Each episode starts in the start state, S and the agent tries to get to the goal state, G in as few steps as possible. There are four movements or actions that can be applied to the environment by the agent:
- up (0)
- right (1)
- down (2)
- left (3)
There is a crosswind running upward through the middle of the grid. The strength of the crosswind is indicated in the center columns of the grid. The strength is added to the vertical displacement of a movement or action, based on the strength indicated for the departing state. For example, if you are one cell to the tight of the goal, the action left will take you to the cell just above the goal.
Tasks are episodic and undiscounted. All rewards are -1 until the goal is reached.
States are numbered from 0 to 69 in this 7 by 10 grid, in a row-wise fashion starting in the top-left corner.
The environment is implemented using the OpenAI Gym library.
3. Agent
The agent is the decision maker. It needs to provide instructions to reach the goal in as few steps as possible while compensating for the effect of the wind. After observing the state of the environment, expressed as a number from 0 to 69 that reflects the current position in the grid, the agent can take one of the following actions:
- up (0)
- right (1)
- down (2)
- left (3)
4. Temporal Difference (TD) Control with Sarsa
We now take the Sarsa prediction algorithm, discussed in part 2 of this series, and turn it into a control algorithm. To do this, we continually estimate \(q_π\) for the behavior policy \(π\), while greedifying \(π\) with respect to \(q_π\).
5. Implementation
Figure 2 shows the algorithm:

Next, we present the code that implements the algorithm.
env = WindyGridworldEnv()5.1 Policy
The following function captures the policy used by the agent:
def create_policy_epsilon_greedy(Q, epsilon, n_A):
def policy_function(observation):
action_probs = np.ones(n_A, dtype=float)*epsilon/n_A
best_action = np.argmax(Q[observation])
#probabilities for each action, length n_A:
action_probs[best_action] += (1.0 - epsilon)
return np.random.choice(np.arange(len(action_probs)), p=action_probs)
return policy_function5.3 Main loop
The following function implements the main loop of the algorithm. It iterates for n_episodes. It also takes a list of monitored_state_actions for which it will record the evolution of action values. This is handy for showing how action values converge during the process.
def td_control_sarsa(env, n_episodes, gamma=1.0, alpha=0.5, epsilon=0.1, monitored_state_actions=None, diag=False):
Q = defaultdict(lambda: np.zeros(env.action_space.n))
pi = create_policy_epsilon_greedy(Q, epsilon, env.action_space.n)
monitored_state_action_values = defaultdict(list)
stats = myplot.EpisodeStats(
episode_lengths=np.zeros(n_episodes),
episode_rewards=np.zeros(n_episodes))
for i in range(n_episodes):
if (i + 1)%10 == 0: print("\rEpisode {}/{}".format(i + 1, n_episodes), end=""); sys.stdout.flush()
print(f'\nepisode {i}:') if diag else None
#---initialize St
St = env.reset()
#---choose At from St, using policy derived from Q
At = pi(St)
#---repeat for each step of episode
for t in itertools.count(): #while True:
#---take action At, observe Rt+1, St+1
Stp1, Rtp1, done, _ = env.step(At) # St+1, Rt+1 OR s',r
#---choose At+1 from St+1, using policy derived from Q
Atp1 = pi(Stp1)
print(f"---t={t} St, At, Rt+1, St+1, At+1: {St, At, Rtp1, Stp1, Atp1}") if diag else None
stats.episode_rewards[i] += Rtp1; stats.episode_lengths[i] = t
#---update Q
Q[St][At] = Q[St][At] + alpha*( Rtp1 + gamma*Q[Stp1][Atp1] - Q[St][At] ); print(f"Q[St][At]: {Q[St][At]}") if diag else None
St = Stp1; At = Atp1
if done:
break
#---until St is terminal
if monitored_state_actions:
for msa in monitored_state_actions:
s = msa[0]; a = msa[1]
# print("\rQ[{}]: {}".format(msa, Q[s][a]), end=""); sys.stdout.flush()
monitored_state_action_values[msa].append(Q[s][a])
return Q, stats, monitored_state_action_values5.4 Monitored state-actions
Let’s pick a number of state-actions to monitor. Each tuple captures the state number (0 to 69) and an action (0, 1, 2, 3).
monitored_state_actions = [(0, 1), (7, 3), (57, 2), (68, 0)]Q,stats,monitored_state_action_values = td_control_sarsa(
env,
n_episodes=1,
alpha=0.5,
monitored_state_actions=monitored_state_actions,
diag=False)Qdefaultdict(<function __main__.td_control_sarsa.<locals>.<lambda>>,
{0: array([-2.40625 , -2.765625, -2.625 , -2.78125 ]),
1: array([-2.76171875, -2.72070312, -3.15234375, -2.9453125 ]),
2: array([-3.58433533, -3.22265625, -3.25072479, -3.43310547]),
3: array([-4.92908859, -4.30065155, -4.68163109, -4.05036354]),
4: array([-4.75071716, -5.15637207, -4.51269531, -4.63743973]),
5: array([-5.80493164, -5.41625977, -5.68017578, -5.22919655]),
6: array([-5.51248169, -5.14805222, -4.84179688, -5.17443848]),
7: array([-5.35997581, -5.01386404, -5.59478283, -5.08129883]),
8: array([-5.2131035 , -4.51734388, -4.69271088, -4.94116211]),
9: array([-3.90070534, -4.53792532, -3.80491407, -4.49000549]),
10: array([-2.6640625, -2.6640625, -2.5390625, -2.546875 ]),
11: array([-2.7578125 , -2.74414062, -2.77929688, -2.6953125 ]),
12: array([-2.81054688, -2.5078125 , -2.62597656, -2.984375 ]),
13: array([-3.0234375 , -3.44042969, -3.49118042, -3.52523804]),
14: array([-3.37109375, -4.00183105, -2.92010498, -3.36053467]),
15: array([-2.76123047, 0. , 0. , 0. ]),
17: array([-3.75195312, -3.69727188, -2.4979248 , -2.72412109]),
18: array([-3.46702576, -3.78730202, -3.39916992, -4.08657074]),
19: array([-3.70444989, -3.2865181 , -2.929245 , -3.27368164]),
20: array([-2.4765625, -2.234375 , -1.8125 , -1.8125 ]),
21: array([-2.3046875, -2.3359375, -2.2421875, -2.1875 ]),
22: array([-2.046875 , -2.13671875, -2.265625 , -2. ]),
23: array([-2.96523666, -2.33300781, -1.5625 , -2.34765625]),
24: array([-2.32128906, -0.5 , -0.75 , -1.80078125]),
25: array([-3.00300026, 0. , 0. , 0. ]),
27: array([-2.73974609, -2.61587572, -1.51806641, 0. ]),
28: array([-3.34075779, -2.52055359, -1.25 , -1.96435547]),
29: array([-2.42333984, -2.3828125 , -2.26806641, -2.12109375]),
30: array([-1.6875 , -2.03125, -1.625 , -1.8125 ]),
31: array([-1.6875 , -1.84375 , -1.765625, -2. ]),
32: array([-2.33984375, -1.34375 , -1.25 , -1.5 ]),
33: array([-1.7265625, -0.75 , -0.75 , -1.15625 ]),
34: array([-1.89746094, -0.5 , 0. , 0. ]),
37: array([0., 0., 0., 0.]),
38: array([-1.54003906, -1.87109375, -0.75 , -0.875 ]),
39: array([-2.03613281, -2.03125 , -1.609375 , -1.53125 ]),
40: array([-1.75 , -1.5625, -1.125 , -1. ]),
41: array([-1.75 , -1.4375, -1.125 , -1.5 ]),
42: array([-1. , -1.125, -0.75 , -1.125]),
43: array([-0.75, -0.75, -0.75, -1. ]),
44: array([-0.5, 0. , 0. , 0. ]),
48: array([-0.875, -1.125, -0.75 , -0.5 ]),
49: array([-1.1875, -1.125 , -1.125 , -0.875 ]),
50: array([-1.125, -1. , -1.125, -1. ]),
51: array([-1.375, -0.75 , -0.75 , -1. ]),
52: array([-1. , -0.5, -0.5, 0. ]),
53: array([ 0. , -0.5, 0. , 0. ]),
57: array([0., 0., 0., 0.]),
58: array([-0.75 , -0.875, 0. , 0. ]),
59: array([-0.75, -0.75, -0.5 , -0.75]),
60: array([-1.125, -1. , -0.75 , -1. ]),
61: array([-1.125, -0.5 , -0.5 , -0.5 ]),
62: array([-0.5, -0.5, 0. , 0. ]),
63: array([-0.5, 0. , 0. , 0. ]),
68: array([0., 0., 0., 0.]),
69: array([-0.5, 0. , 0. , 0. ])})Q[50]array([-1.125, -1. , -1.125, -1. ])Q[7][0], Q[7][1], Q[7][2], Q[7][3](-5.359975814819336, -5.013864040374756, -5.594782829284668, -5.081298828125)print(monitored_state_actions[0])
print(monitored_state_action_values[monitored_state_actions[0]])(0, 1)
[-2.765625]# last value in monitored_state_actions should be value in Q
msa = monitored_state_actions[0]; print('msa:', msa)
s = msa[0]; print('s:', s)
a = msa[1]; print('a:', a)
monitored_state_action_values[msa][-1], Q[s][a] #monitored_stuff[msa] BUT Q[s][a]msa: (0, 1)
s: 0
a: 1(-2.765625, -2.765625)5.5 Run 1
Q1,stats,monitored_state_action_values1 = td_control_sarsa(
env,
n_episodes=20,
alpha=0.5,
monitored_state_actions=monitored_state_actions,
diag=False)Episode 20/20# last value in monitored_state_actions should be value in Q
msa = monitored_state_actions[0]; print('msa:', msa)
s = msa[0]; print('s:', s)
a = msa[1]; print('a:', a)
monitored_state_action_values1[msa][-1], Q1[s][a] #monitored_stuff[msa] BUT Q[s][a]msa: (0, 1)
s: 0
a: 1(-7.683773674536496, -7.683773674536496)5.5.1 Monitored state-actions
The following chart shows how the values of the 4 monitored state-actions converge to their values:
plt.rcParams["figure.figsize"] = (18,10)
for msa in monitored_state_actions:
plt.plot(monitored_state_action_values1[msa])
plt.title('Estimated $q_\pi(s,a)$ for some state-actions', fontsize=18)
plt.xlabel('Episodes', fontsize=16)
plt.ylabel('Estimated $q_\pi(s,a)$', fontsize=16)
plt.legend(monitored_state_actions, fontsize=16)
plt.show()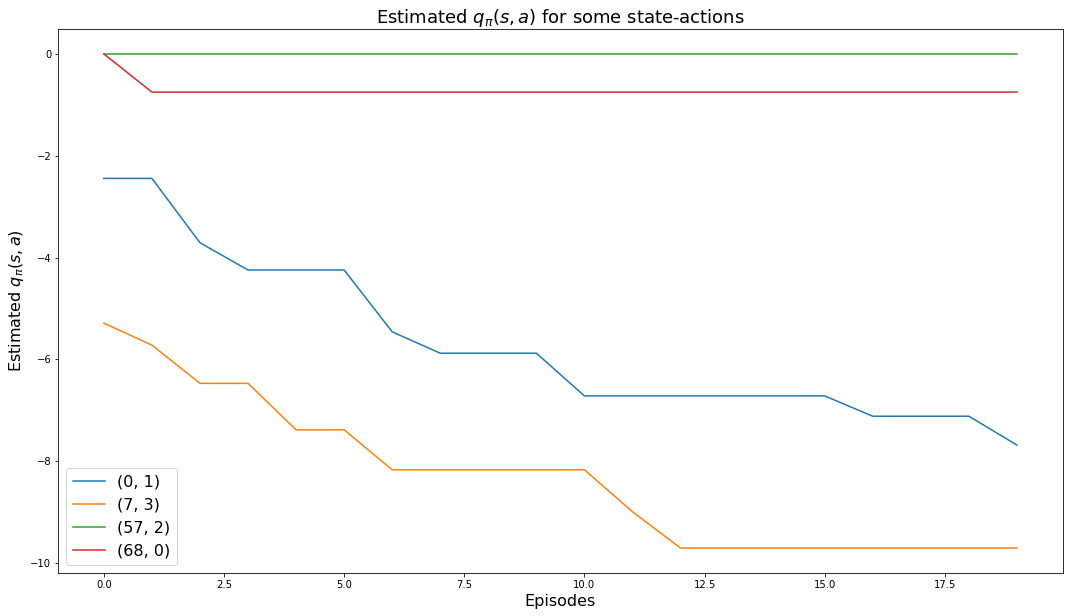
5.5.2 Other metrics
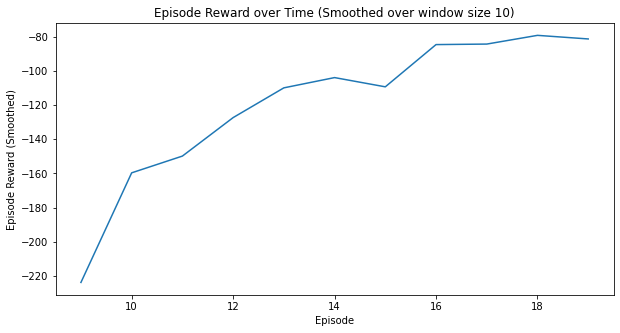
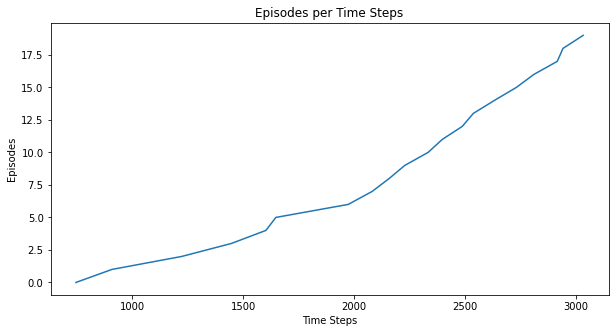
Here are some additional metrics:
myplot.plot_episode_stats(stats);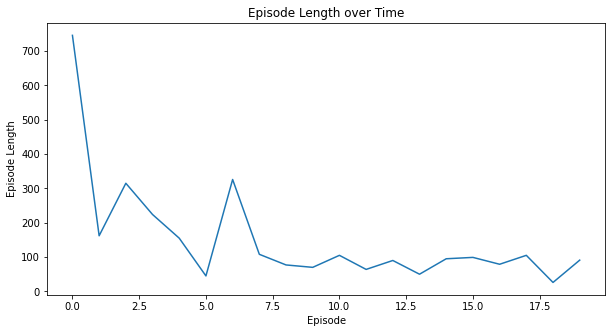
5.5.3 State-value function
To make a plot of the state-value function we derive the state-value function from the action-value function:
# create state-value function from action-value function
V1 = defaultdict(float)
for state, actions in Q1.items():
action_value = np.max(actions)
V1[state] = action_valueTo make a plot of the state-value function we reshape the values to align with the Windy Gridworld pattern.
# convert V1 to V1p for plotting
states_shape = (7, 10)
nS = np.prod(states_shape)
V1p = {}
for s in range(nS):
position = np.unravel_index(s, states_shape); #print(f"position: {position}")
V1p[position] = V1[s]V1p{(0, 0): -7.271114991977811,
(0, 1): -7.365369761191687,
(0, 2): -7.820390481802624,
(0, 3): -8.601699936656795,
(0, 4): -9.42239515932238,
(0, 5): -10.055318695787552,
(0, 6): -9.136864999404239,
(0, 7): -8.113809599439666,
(0, 8): -7.102886592467121,
(0, 9): -6.122323010966197,
(1, 0): -7.033107928931713,
(1, 1): -7.000523722963408,
(1, 2): -7.3842934768317745,
(1, 3): -7.543648810351215,
(1, 4): -7.1979487480434585,
(1, 5): -8.816178446702644,
(1, 6): -6.410089408456323,
(1, 7): -5.747465054922031,
(1, 8): -5.633030942836285,
(1, 9): -5.121980307446879,
(2, 0): -6.632856905460358,
(2, 1): -6.410806593485177,
(2, 2): -6.610843314578233,
(2, 3): -6.491644859226653,
(2, 4): -7.068332486801211,
(2, 5): -4.523205320525449,
(2, 6): -4.527344256141326,
(2, 7): -4.375629678368568,
(2, 8): -4.8553969180211425,
(2, 9): -4.079820136166134,
(3, 0): -6.3231203109025955,
(3, 1): -6.029869761317968,
(3, 2): -5.7604038417339325,
(3, 3): -6.43234196503181,
(3, 4): -4.791913981884136,
(3, 5): -3.732886193602231,
(3, 6): -3.0675412714481354,
(3, 7): 0.0,
(3, 8): -3.7871122136712074,
(3, 9): -3.030426986340899,
(4, 0): -6.010084867477417,
(4, 1): -5.5859046168625355,
(4, 2): -5.15749467164278,
(4, 3): -4.519403687416343,
(4, 4): -3.788623766391538,
(4, 5): -1.5625,
(4, 6): 0.0,
(4, 7): 0.0,
(4, 8): -0.9999980926513672,
(4, 9): -2.0051047801971436,
(5, 0): -5.2519211769104,
(5, 1): -4.902651786804199,
(5, 2): -4.3546342849731445,
(5, 3): -3.9795570373535156,
(5, 4): -2.2826366424560547,
(5, 5): 0.0,
(5, 6): 0.0,
(5, 7): 0.0,
(5, 8): -0.875,
(5, 9): -1.546875,
(6, 0): -5.070953369140625,
(6, 1): -4.431668281555176,
(6, 2): -3.5974831581115723,
(6, 3): -2.82666015625,
(6, 4): 0.0,
(6, 5): 0.0,
(6, 6): 0.0,
(6, 7): 0.0,
(6, 8): -0.75,
(6, 9): -0.75}myplot.plot_state_value_surface(V1p, title='State-Value Function for Windy Gridworld', wireframe=True, azim=-150, elev=60);/usr/local/lib/python3.7/dist-packages/numpy/core/_asarray.py:136: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return array(a, dtype, copy=False, order=order, subok=True)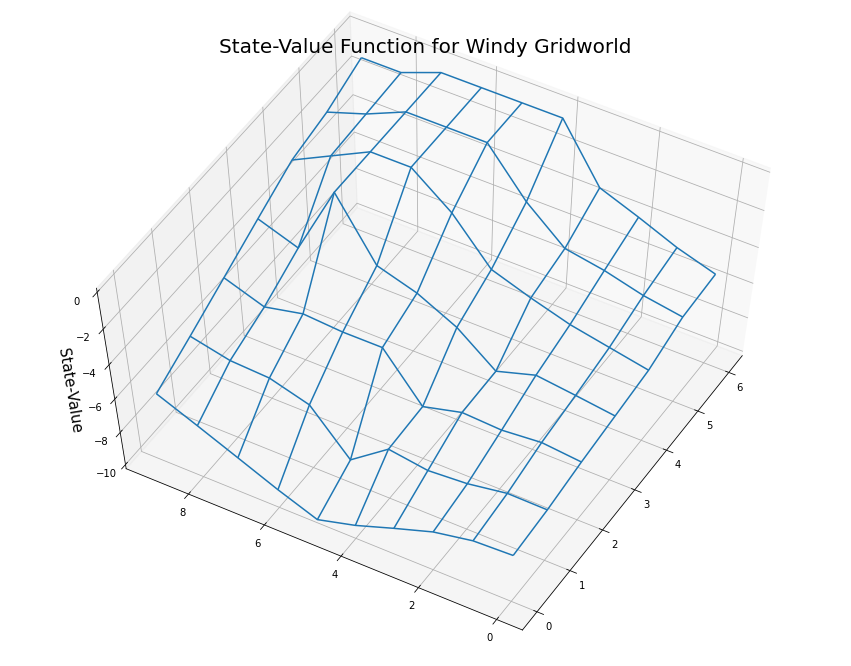
myplot.plot_state_value_surface(V1p, title='State-Value Function for Windy Gridworld', wireframe=False, azim=-150, elev=60);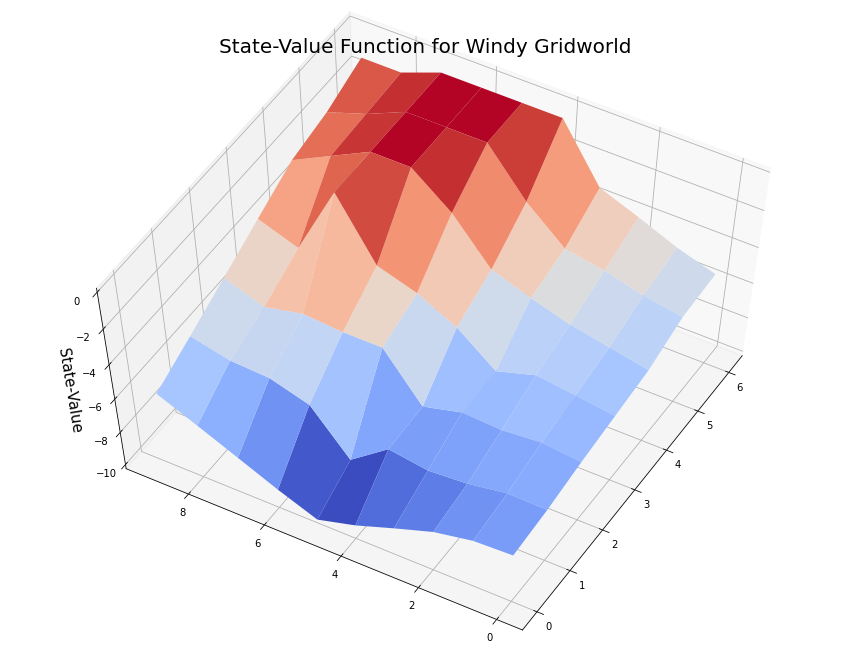
myplot.plot_state_value_heatmap_windy_gridworld(V1p, title='State-Value Function for Windy Gridworld');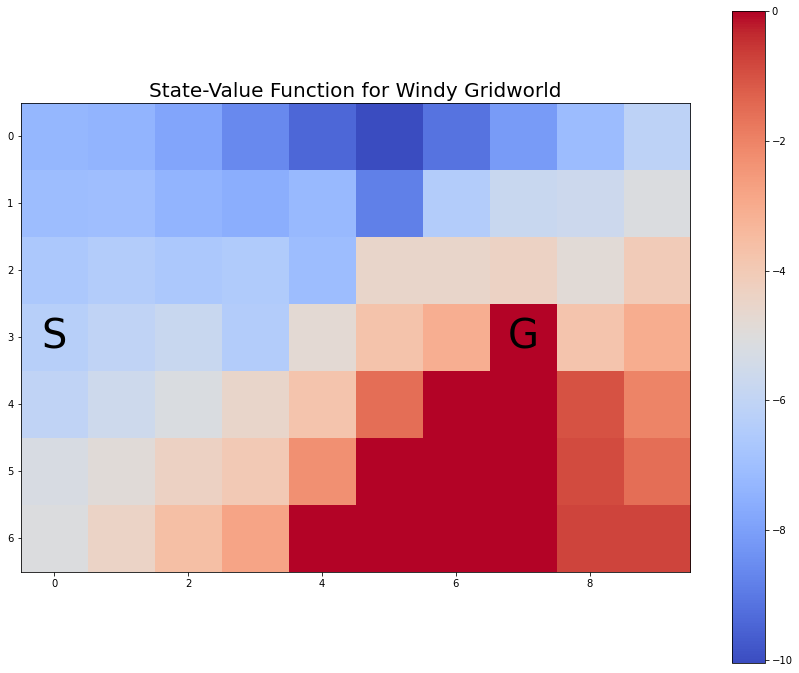
5.5.4 Policy function
# create policy function from action-value function
P1 = defaultdict(float)
for state, actions in Q1.items():
action = np.argmax(actions)
P1[state] = action# convert P1 to P1p for plotting
states_shape = (7, 10)
nS = np.prod(states_shape)
P1p = {}
for s in range(nS):
position = np.unravel_index(s, states_shape); #print(f"position: {position}")
P1p[position] = P1[s]myplot.plot_policy_windy_gridworld(P1p, title='Policy Function for Windy Gridworld');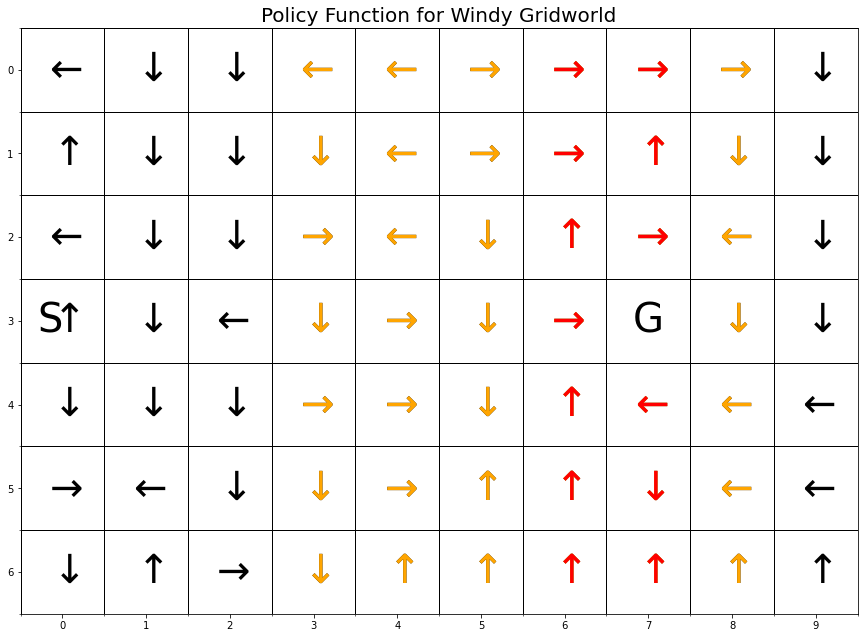
The graphic above does not show a path from S to G. More training is needed. Note that the states with the orange arrows are subject to an upward wind drift of 1 cell, and the states with the red arrows are subject to an upward drift of 2 cells.
5.6 Run 2
Q2,stats,monitored_state_action_values2 = td_control_sarsa(
env,
n_episodes=500,
alpha=0.5,
monitored_state_actions=monitored_state_actions,
diag=False)Episode 500/500# last value in monitored_state_actions should be value in Q
msa = monitored_state_actions[0]; print('msa:', msa)
s = msa[0]; print('s:', s)
a = msa[1]; print('a:', a)
monitored_state_action_values2[msa][-1], Q2[s][a] #monitored_stuff[msa] BUT Q[s][a]msa: (0, 1)
s: 0
a: 1(-17.349018722302546, -17.349018722302546)5.6.1 Monitored state-actions
The following chart shows how the values of the monitored state-actions converge to their values:
plt.rcParams["figure.figsize"] = (18,10)
for msa in monitored_state_actions:
plt.plot(monitored_state_action_values2[msa])
plt.title('Estimated $q_\pi(s,a)$ for some state-actions', fontsize=18)
plt.xlabel('Episodes', fontsize=16)
plt.ylabel('Estimated $q_\pi(s,a)$', fontsize=16)
plt.legend(monitored_state_actions, fontsize=16)
plt.show()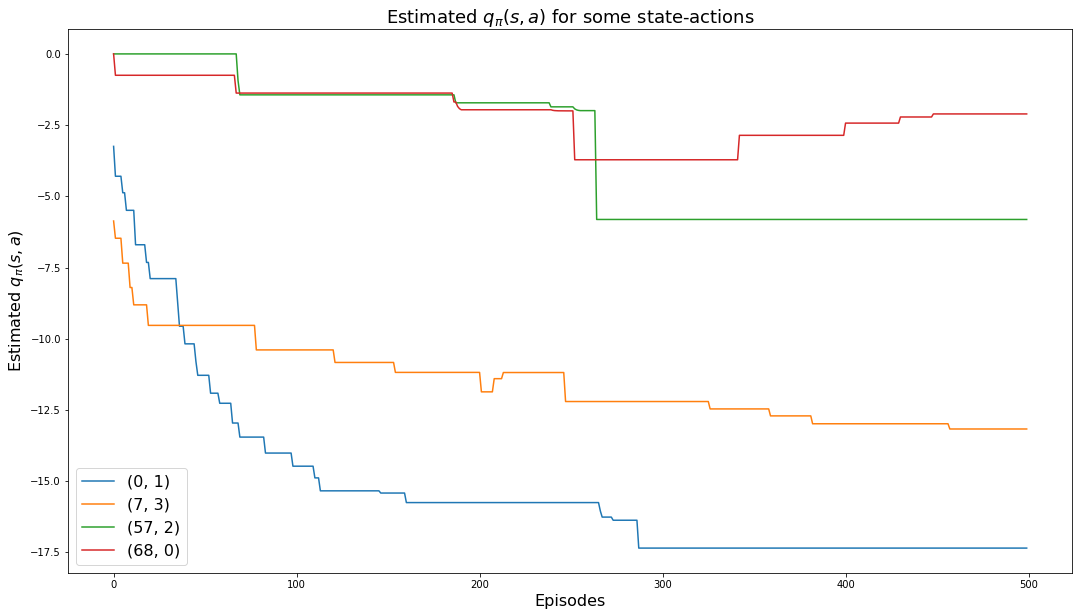
5.6.2 Other metrics
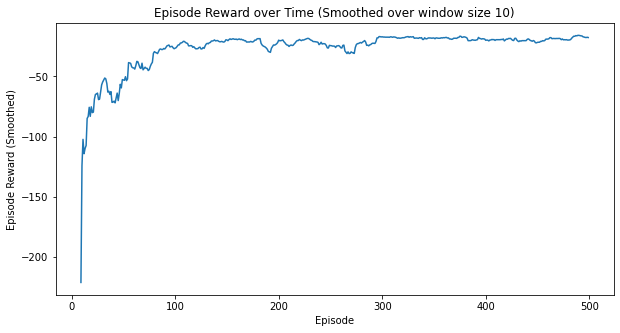
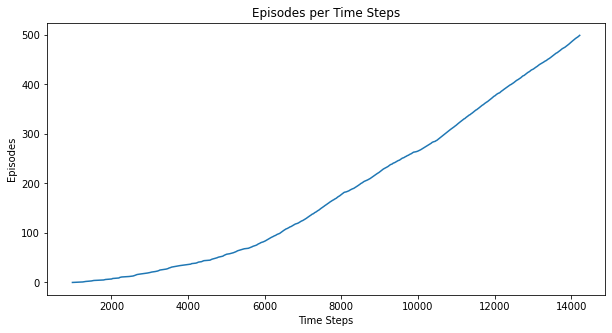
Here are some additional metrics:
myplot.plot_episode_stats(stats);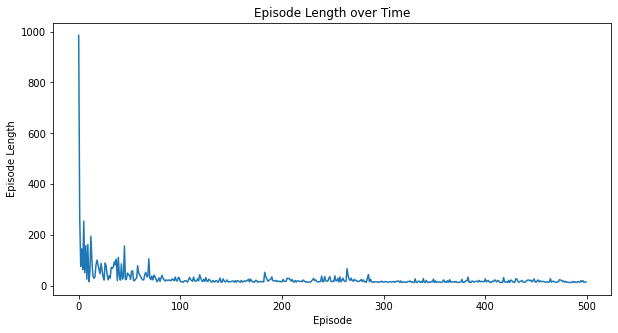
5.6.3 State-value function
To make a plot of the state-value function we reshape the values to align with the Windy Gridworld pattern.
# create state-value function from action-value function
V2 = defaultdict(float)
for state, actions in Q2.items():
action_value = np.max(actions)
V2[state] = action_value# convert V2 to V2p for plotting
states_shape = (7, 10)
nS = np.prod(states_shape)
V2p = {}
for s in range(nS):
position = np.unravel_index(s, states_shape); #print(f"position: {position}")
V2p[position] = V2[s]V2p{(0, 0): -16.973377439534794,
(0, 1): -16.755329301731475,
(0, 2): -16.189905841206382,
(0, 3): -14.495628716710335,
(0, 4): -13.519974101345873,
(0, 5): -11.098242125070652,
(0, 6): -10.214938102010041,
(0, 7): -9.117234596494264,
(0, 8): -8.290319391189001,
(0, 9): -7.126637570125348,
(1, 0): -17.09939488444438,
(1, 1): -16.389647157803992,
(1, 2): -15.76006054783221,
(1, 3): -15.46347301576851,
(1, 4): -12.701984465357024,
(1, 5): -11.071513515678372,
(1, 6): -10.012305563375172,
(1, 7): -9.601096482259496,
(1, 8): -9.196118192323981,
(1, 9): -5.834609951150981,
(2, 0): -17.654737939797993,
(2, 1): -16.642761718094278,
(2, 2): -15.533810463168841,
(2, 3): -14.8323425551226,
(2, 4): -12.425784123059197,
(2, 5): -11.33358662269242,
(2, 6): -11.472404745891701,
(2, 7): -9.37014599183043,
(2, 8): -8.24654787456487,
(2, 9): -4.5051749110027615,
(3, 0): -17.5792849127954,
(3, 1): -15.505495214076022,
(3, 2): -14.294551972063864,
(3, 3): -13.473997069408396,
(3, 4): -12.697607540929733,
(3, 5): -12.203095473676408,
(3, 6): -10.485800921967407,
(3, 7): 0.0,
(3, 8): -7.749496335417689,
(3, 9): -3.148503012498557,
(4, 0): -16.48952176149206,
(4, 1): -15.375661920550924,
(4, 2): -15.193163657426915,
(4, 3): -13.626861013926733,
(4, 4): -13.128121986991863,
(4, 5): -11.826189655247406,
(4, 6): 0.0,
(4, 7): -0.999999999992724,
(4, 8): -1.0,
(4, 9): -2.000458398513726,
(5, 0): -16.86583191668052,
(5, 1): -16.072472068178087,
(5, 2): -15.128963487582759,
(5, 3): -14.132961124259996,
(5, 4): -12.656043977048583,
(5, 5): 0.0,
(5, 6): 0.0,
(5, 7): -4.805760539792474,
(5, 8): -6.040767109806627,
(5, 9): -5.169961947697285,
(6, 0): -16.149758797246967,
(6, 1): -15.544144670714475,
(6, 2): -14.444778361652368,
(6, 3): -13.579038277480413,
(6, 4): 0.0,
(6, 5): 0.0,
(6, 6): 0.0,
(6, 7): 0.0,
(6, 8): -2.1072756283541456,
(6, 9): -3.475358010772281}myplot.plot_state_value_surface(V2p, title='State-Value Function for Windy Gridworld', wireframe=False, azim=-150, elev=60);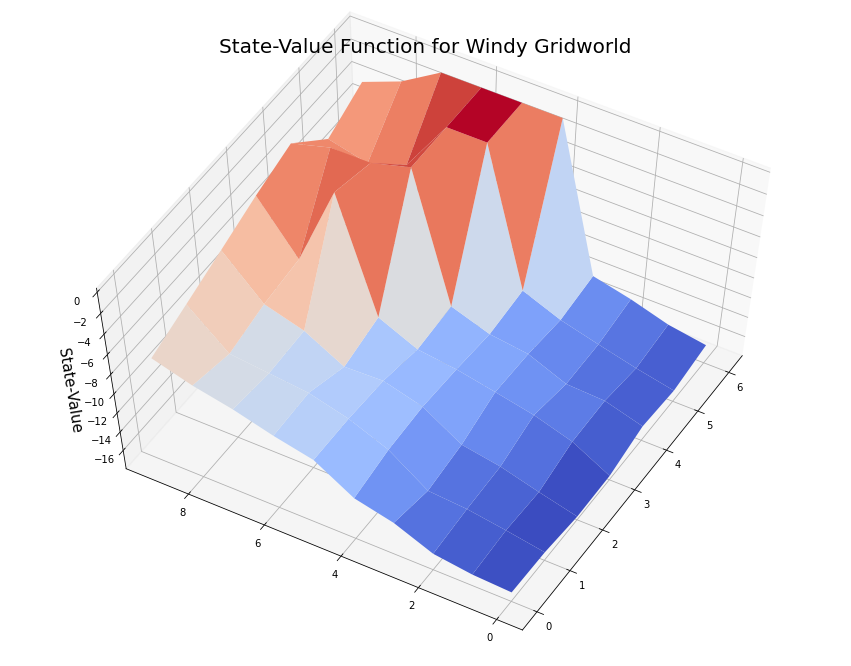
myplot.plot_state_value_heatmap_windy_gridworld(V2p, title='State-Value Function for Windy Gridworld');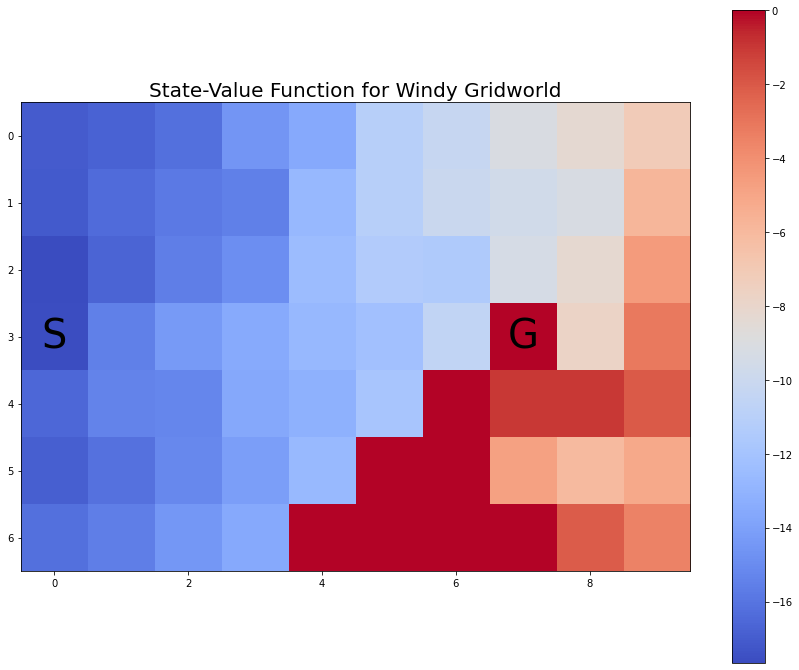
5.6.4 Policy function
# create policy function from action-value function
P2 = defaultdict(float)
for state, actions in Q2.items():
action = np.argmax(actions)
P2[state] = action# convert P2 to P2p for plotting
states_shape = (7, 10)
nS = np.prod(states_shape)
P2p = {}
for s in range(nS):
position = np.unravel_index(s, states_shape); #print(f"position: {position}")
P2p[position] = P2[s]opt_path = [
(3,0),(4,0),(4,1),(4,2),(4,3),(3,4),(2,5),(1,6),(0,7),(0,8),(0,9),(1,9),(2,9),(3,9),(4,9),(4,8),(3,7)]
myplot.plot_policy_windy_gridworld(
P2p,
title='Policy Function for Windy Gridworld',
highlight_cells=opt_path,
highlight_color='lightgreen');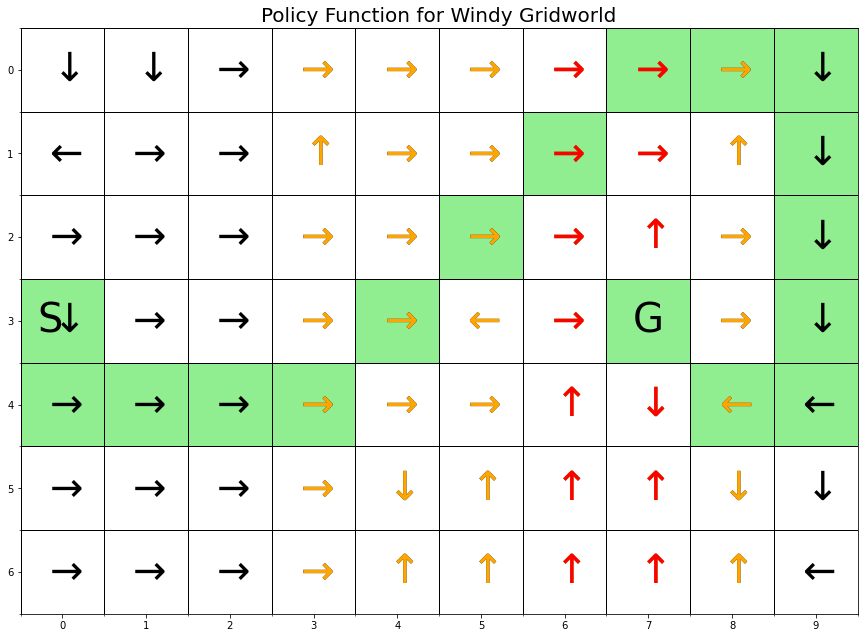
The graphic above shows the optimal path from S to G. Note that the states with the orange arrows are subject to an upward wind drift of 1 cell, and the states with the red arrows are subject to an upward drift of 2 cells.