The cart-pole problem can be considered as the “Hello World” problem of Reinforcement Learning (RL). It was described by Barto (1983). The physics of the system is as follows:
All motion happens in a vertical plane
A hinged pole is attached to a cart
The cart slides horizontally on a track in an effort to balance the pole vertically
The system has four state variables:
\(x\): displacement of the cart
\(\theta\): vertical angle on the pole
\(\dot{x}\): velocity of the cart
\(\dot{\theta}\): angular velocity of the pole
Here is a graphical representation of the system:
Cartpole environment
2. Purpose
The purpose of our activity in this blog post is to construct and train an entity, let’s call it a controller, that can manage the horizontal motions of the cart so that the pole remains as close to vertical as possible. The controlled entity is, of course, the cart and pole system.
3. RLlib Setup
We will use the Ray RLlib framework. In addition, this notebook will be run in Google Collab.
Here we specify all the hyperparameters for the problem:
N_ITERATIONS =10#number of training runsconfig = ppo.DEFAULT_CONFIG.copy()config["log_level"] ="WARN"config["num_workers"] =1#use > 1 for using more CPU cores, including over a clusterconfig["num_sgd_iter"] =10#number of SGD (stochastic gradient descent) iterations per training minibatchconfig["sgd_minibatch_size"] =250config["model"]["fcnet_hiddens"] = [100, 50]config["num_cpus_per_worker"] =0#avoids running out of resources in the notebook environment when this cell is re-executed
5. Environment
Let’s start with the controlled entity. In Reinforcement Learning, the controlled entity is known as an environment. We make use of an environment provided by the OpenAI Gym framework, known as “CartPole-v1”.
import gymenv = gym.make("CartPole-v1")
Input to Environment
Actions to the environment come from an action space with a size of 2.
env.action_space
Discrete(2)
We will use the convention that the action on the cart is as follows:
0 means LEFT
1 means RIGHT
Evolution of the Environment
The arrival of an action at the input of the environment leads to the update of its state. This is how the environment evolves. To advance the state of the environment, the environment.step method takes an input action and applies it to the environment.
The next fragment of code drives the environment through 30 steps by applying random actions:
env.reset()for i inrange(30): observation, reward, done, info = env.step(env.action_space.sample())print("step", i, observation, reward, done, info)env.close()
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
libxxf86dga1
Suggested packages:
mesa-utils
The following NEW packages will be installed:
libxxf86dga1 x11-utils xvfb
0 upgraded, 3 newly installed, 0 to remove and 37 not upgraded.
Need to get 994 kB of archives.
After this operation, 2,981 kB of additional disk space will be used.
Get:1 http://archive.ubuntu.com/ubuntu bionic/main amd64 libxxf86dga1 amd64 2:1.1.4-1 [13.7 kB]
Get:2 http://archive.ubuntu.com/ubuntu bionic/main amd64 x11-utils amd64 7.7+3build1 [196 kB]
Get:3 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 xvfb amd64 2:1.19.6-1ubuntu4.9 [784 kB]
Fetched 994 kB in 1s (839 kB/s)
Selecting previously unselected package libxxf86dga1:amd64.
(Reading database ... 155222 files and directories currently installed.)
Preparing to unpack .../libxxf86dga1_2%3a1.1.4-1_amd64.deb ...
Unpacking libxxf86dga1:amd64 (2:1.1.4-1) ...
Selecting previously unselected package x11-utils.
Preparing to unpack .../x11-utils_7.7+3build1_amd64.deb ...
Unpacking x11-utils (7.7+3build1) ...
Selecting previously unselected package xvfb.
Preparing to unpack .../xvfb_2%3a1.19.6-1ubuntu4.9_amd64.deb ...
Unpacking xvfb (2:1.19.6-1ubuntu4.9) ...
Setting up xvfb (2:1.19.6-1ubuntu4.9) ...
Setting up libxxf86dga1:amd64 (2:1.1.4-1) ...
Setting up x11-utils (7.7+3build1) ...
Processing triggers for man-db (2.8.3-2ubuntu0.1) ...
Processing triggers for libc-bin (2.27-3ubuntu1.3) ...
/sbin/ldconfig.real: /usr/local/lib/python3.7/dist-packages/ideep4py/lib/libmkldnn.so.0 is not a symbolic link
Collecting pyvirtualdisplay==0.2.*
Downloading PyVirtualDisplay-0.2.5-py2.py3-none-any.whl (13 kB)
Collecting EasyProcess
Downloading EasyProcess-0.3-py2.py3-none-any.whl (7.9 kB)
Installing collected packages: EasyProcess, pyvirtualdisplay
Successfully installed EasyProcess-0.3 pyvirtualdisplay-0.2.5
from pyvirtualdisplay import Displaydisplay = Display(visible=False, size=(1400, 900))_ = display.start()
from gym.wrappers.monitoring.video_recorder import VideoRecorderbefore_training ="before_training.mp4"video = VideoRecorder(env, before_training)# returns an initial observationenv.reset()for i inrange(200): env.render() video.capture_frame() observation, reward, done, info = env.step(env.action_space.sample())video.close()env.close()
/usr/local/lib/python3.7/dist-packages/gym/logger.py:30: UserWarning: WARN: You are calling 'step()' even though this environment has already returned done = True. You should always call 'reset()' once you receive 'done = True' -- any further steps are undefined behavior.
warnings.warn(colorize('%s: %s'%('WARN', msg % args), 'yellow'))
from base64 import b64encodedef render_mp4(videopath: str) ->str:""" Gets a string containing a b4-encoded version of the MP4 video at the specified path. """ mp4 =open(videopath, 'rb').read() base64_encoded_mp4 = b64encode(mp4).decode()returnf'<video width=400 controls><source src="data:video/mp4;' \f'base64,{base64_encoded_mp4}" type="video/mp4"></video>'
from IPython.display import HTMLhtml = render_mp4(before_training)HTML(html)
Output from Environment
The output from the environment returns a tuple containing:
the next observation of the environment
the reward
a flag indicating whether the episode is done
some other information
6. Agent
The controller in our problem is the algorithm used to solve the problem. In RL parlance the controller is known as an Agent. RLlib provides implementations of a variety of Agents.
For our problem we will use the PPO agent.
The fundamental problem for an Agent is how to find the next best action to submit to the environment.
7. Train the agent
ENV ="CartPole-v1"#OpenAI Gym environment for Cart Pole
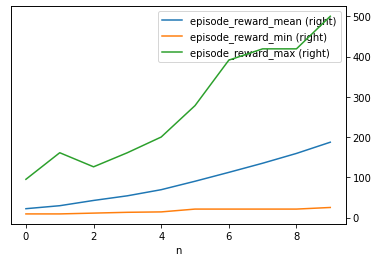
agent = ppo.PPOTrainer(config, env=ENV)results = []episode_data = []episode_json = []for n inrange(N_ITERATIONS): result = agent.train() results.append(result) episode = {'n': n, 'episode_reward_min': result['episode_reward_min'], 'episode_reward_mean': result['episode_reward_mean'], 'episode_reward_max': result['episode_reward_max'], 'episode_len_mean': result['episode_len_mean']} episode_data.append(episode) episode_json.append(json.dumps(episode)) file_name = agent.save(CHECKPOINT_ROOT)print(f'{n:3d}: Min/Mean/Max reward: {result["episode_reward_min"]:8.4f}/{result["episode_reward_mean"]:8.4f}/{result["episode_reward_max"]:8.4f}. Checkpoint saved to {file_name}')
2021-11-30 01:09:32,414 INFO trainer.py:753 -- Tip: set framework=tfe or the --eager flag to enable TensorFlow eager execution
2021-11-30 01:09:32,416 INFO ppo.py:167 -- In multi-agent mode, policies will be optimized sequentially by the multi-GPU optimizer. Consider setting simple_optimizer=True if this doesn't work for you.
2021-11-30 01:09:32,418 INFO trainer.py:772 -- Current log_level is WARN. For more information, set 'log_level': 'INFO' / 'DEBUG' or use the -v and -vv flags.
(pid=482) 2021-11-30 01:09:37,858 WARNING deprecation.py:39 -- DeprecationWarning: `SampleBatch['is_training']` has been deprecated. Use `SampleBatch.is_training` instead. This will raise an error in the future!
2021-11-30 01:09:39,395 WARNING deprecation.py:39 -- DeprecationWarning: `SampleBatch['is_training']` has been deprecated. Use `SampleBatch.is_training` instead. This will raise an error in the future!
2021-11-30 01:09:40,446 WARNING trainer_template.py:186 -- `execution_plan` functions should accept `trainer`, `workers`, and `config` as args!
2021-11-30 01:09:40,457 WARNING util.py:57 -- Install gputil for GPU system monitoring.
2021-11-30 01:09:46,319 WARNING deprecation.py:39 -- DeprecationWarning: `slice` has been deprecated. Use `SampleBatch[start:stop]` instead. This will raise an error in the future!
0: Min/Mean/Max reward: 9.0000/ 21.9725/ 95.0000. Checkpoint saved to /content/gdrive/My Drive/RLlib/checkpoints/ppo/cart/checkpoint_000001/checkpoint-1
1: Min/Mean/Max reward: 9.0000/ 29.3971/161.0000. Checkpoint saved to /content/gdrive/My Drive/RLlib/checkpoints/ppo/cart/checkpoint_000002/checkpoint-2
2: Min/Mean/Max reward: 11.0000/ 42.4400/126.0000. Checkpoint saved to /content/gdrive/My Drive/RLlib/checkpoints/ppo/cart/checkpoint_000003/checkpoint-3
3: Min/Mean/Max reward: 13.0000/ 53.9900/161.0000. Checkpoint saved to /content/gdrive/My Drive/RLlib/checkpoints/ppo/cart/checkpoint_000004/checkpoint-4
4: Min/Mean/Max reward: 14.0000/ 69.1700/200.0000. Checkpoint saved to /content/gdrive/My Drive/RLlib/checkpoints/ppo/cart/checkpoint_000005/checkpoint-5
5: Min/Mean/Max reward: 21.0000/ 90.1300/278.0000. Checkpoint saved to /content/gdrive/My Drive/RLlib/checkpoints/ppo/cart/checkpoint_000006/checkpoint-6
6: Min/Mean/Max reward: 21.0000/112.2200/391.0000. Checkpoint saved to /content/gdrive/My Drive/RLlib/checkpoints/ppo/cart/checkpoint_000007/checkpoint-7
7: Min/Mean/Max reward: 21.0000/134.9200/419.0000. Checkpoint saved to /content/gdrive/My Drive/RLlib/checkpoints/ppo/cart/checkpoint_000008/checkpoint-8
8: Min/Mean/Max reward: 21.0000/159.2900/419.0000. Checkpoint saved to /content/gdrive/My Drive/RLlib/checkpoints/ppo/cart/checkpoint_000009/checkpoint-9
9: Min/Mean/Max reward: 25.0000/187.1200/500.0000. Checkpoint saved to /content/gdrive/My Drive/RLlib/checkpoints/ppo/cart/checkpoint_000010/checkpoint-10
after_training ="after_training.mp4"after_video = VideoRecorder(env, after_training)observation = env.reset()done =Falsewhilenot done: env.render() after_video.capture_frame() action = agent.compute_action(observation) observation, reward, done, info = env.step(action)after_video.close()env.close()# You should get a video similar to the one below. html = render_mp4(after_training)HTML(html)
2021-11-30 01:13:24,634 WARNING deprecation.py:39 -- DeprecationWarning: `compute_action` has been deprecated. Use `compute_single_action` instead. This will raise an error in the future!