What is Abalone? It is a large marine gastropod mollusk that lives in coastal saltwater and is a member of the Haliotidae family. Abalone is often found around the waters of South Africa, Australia, New Zealand, Japan, and the west coast of North America. The abalone shell is flat and spiral-shaped with several small holes around the edges. It has a single shell on top with a large foot to cling to rocks and lives on algae. Sizes range from 4 to 10 inches. The interior of the shell has an iridescent mother of pearl appearance (Figure 1).
Figure 1 Abalone shell
As a highly prized culinary delicacy (Figure 2), it has a rich, flavorful taste that is sweet buttery, and salty. Abalone is often sold live in the shell, but also frozen, or canned. It is among the world’s most expensive seafood. For preparation it is often cut into thick steaks and pan-fried. It can also be eaten raw.
Figure 2 Abalone ready for the eating
2. Data Understanding
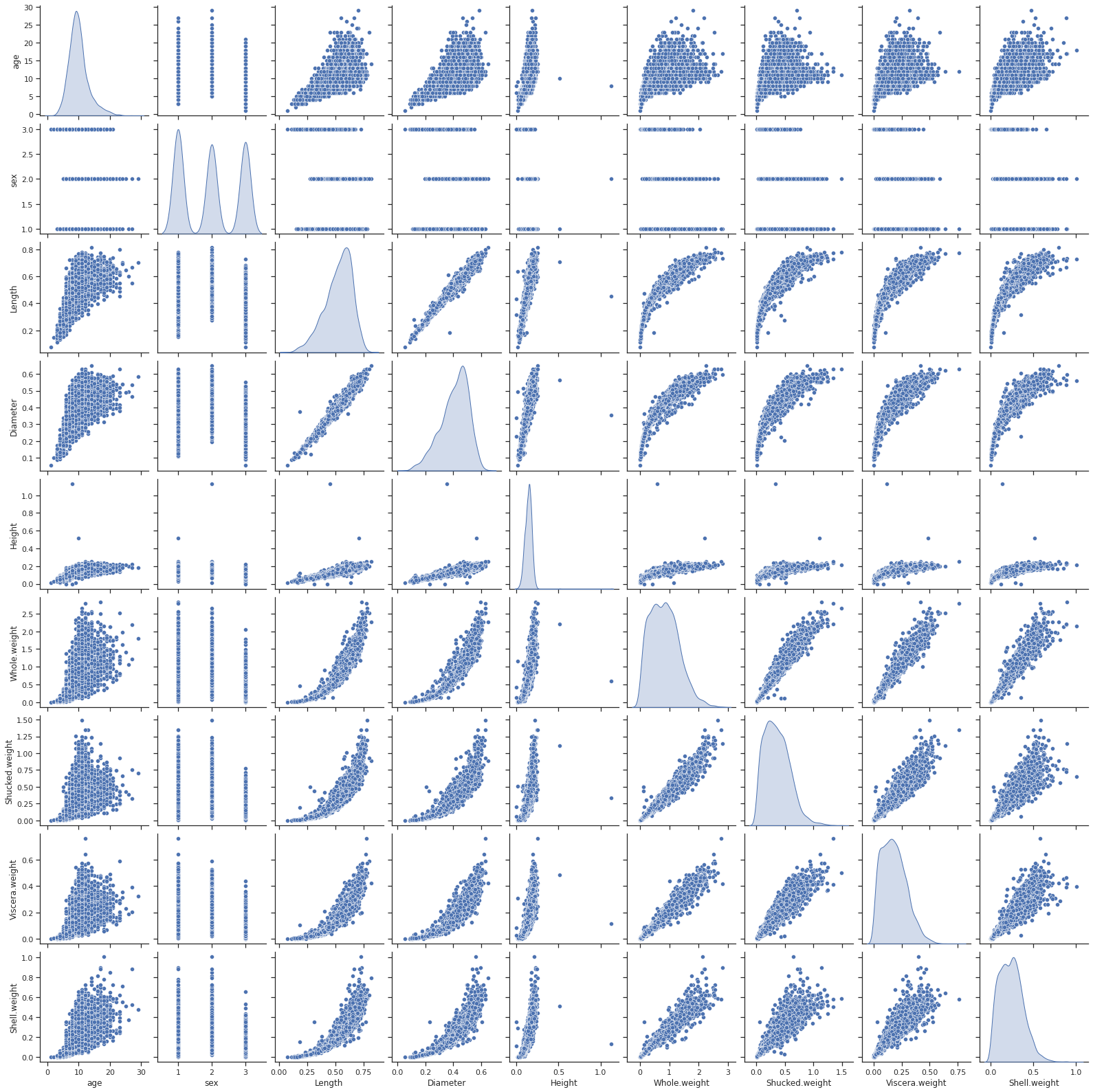
There is more information on the Abalone Dataset available at UCI data repository.
The dataset has 9 features:
Rings (number of)
sex (M, F, Infant)
Length (Longest shell measurement in mm)
Diameter (in mm)
Height (with meat in shell, in mm)
Whole Weight (whole abalone, in grams)
Shucked Weight (weight of meat, in grams)
Viscera Weight (gut weight after bleeding, in grams)
Shell Weight (after being dried, in grams)
The number of rings indicates the age of the abalone. The age of abalone is determined by cutting the shell through the cone, staining it, and counting the number of rings through a microscope. Not only is this a boring and time-consuming task but it is also relatively expensive in terms of waste. The remaining measurements, on the other hand, are readily achievable with the correct tools, and with much less effort. The purpose of this model is to estimate the abalone age, specifically the number of rings, based on the other features.
2.0 Setup
import urllib.requestimport pandas as pdimport seaborn as snsimport random# from IPython.core.debugger import set_traceimport boto3import sagemakerfrom sagemaker.image_uris import retrievefrom time import gmtime, strftimefrom sagemaker.serializers import CSVSerializerfrom sagemaker.deserializers import JSONDeserializer# import json# from itertools import islice# import math# import struct!pip install smdebugfrom smdebug.trials import create_trialimport matplotlib.pyplot as pltimport re
Requirement already satisfied: smdebug in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (1.0.9)
Requirement already satisfied: pyinstrument>=3.1.3 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from smdebug) (3.4.2)
Requirement already satisfied: protobuf>=3.6.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from smdebug) (3.15.2)
Requirement already satisfied: numpy>=1.16.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from smdebug) (1.19.5)
Requirement already satisfied: boto3>=1.10.32 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from smdebug) (1.17.75)
Requirement already satisfied: packaging in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from smdebug) (20.9)
Requirement already satisfied: jmespath<1.0.0,>=0.7.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from boto3>=1.10.32->smdebug) (0.10.0)
Requirement already satisfied: s3transfer<0.5.0,>=0.4.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from boto3>=1.10.32->smdebug) (0.4.2)
Requirement already satisfied: botocore<1.21.0,>=1.20.75 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from boto3>=1.10.32->smdebug) (1.20.75)
Requirement already satisfied: python-dateutil<3.0.0,>=2.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from botocore<1.21.0,>=1.20.75->boto3>=1.10.32->smdebug) (2.8.1)
Requirement already satisfied: urllib3<1.27,>=1.25.4 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from botocore<1.21.0,>=1.20.75->boto3>=1.10.32->smdebug) (1.26.4)
Requirement already satisfied: six>=1.9 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from protobuf>=3.6.0->smdebug) (1.15.0)
Requirement already satisfied: pyinstrument-cext>=0.2.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from pyinstrument>=3.1.3->smdebug) (0.2.4)
Requirement already satisfied: pyparsing>=2.0.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from packaging->smdebug) (2.4.7)
[2021-05-24 13:28:27.782 ip-172-16-88-149:11789 INFO utils.py:27] RULE_JOB_STOP_SIGNAL_FILENAME: None
2.1 Download
The Abalone data is available in the libsvm format. Next, we will download it.
%%time# Load the datasetSOURCE_DATA ="abalone_libsvm.txt"urllib.request.urlretrieve("https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/regression/abalone", SOURCE_DATA)
CPU times: user 18.7 ms, sys: 0 ns, total: 18.7 ms
Wall time: 1.69 s
('abalone_libsvm.txt', <http.client.HTTPMessage at 0x7f1b70d0c198>)
The libsvm format is not suitable to explore the data with pandas. Next we will convert the data to csv format:
# Extracting the features values from the libvsm formatfeatures = ["sex","Length","Diameter","Height","Whole.weight","Shucked.weight","Viscera.weight","Shell.weight",]for f in features:if f =="sex": df[f] = (df[f].str.split(":", n=1, expand=True)[1])else: df[f] = (df[f].str.split(":", n=1, expand=True)[1])df
# upload the files to the S3 bucketupload_to_s3(bucket, prefix, "train", FILE_TRAIN)upload_to_s3(bucket, prefix, "valid", FILE_VALID)upload_to_s3(bucket, prefix, "testg", FILE_TESTG)
Writing to s3://learnableloopai-blog/abalone/train/abalone_train.csv
Writing to s3://learnableloopai-blog/abalone/valid/abalone_valid.csv
Writing to s3://learnableloopai-blog/abalone/testg/abalone_testg.csv
4.2 Setup data channels
s3_train_data =f"s3://{bucket}/{prefix}/train"print(f"training files will be taken from: {s3_train_data}")s3_valid_data =f"s3://{bucket}/{prefix}/valid"print(f"validation files will be taken from: {s3_valid_data}")s3_testg_data =f"s3://{bucket}/{prefix}/testg"print(f"testing files will be taken from: {s3_testg_data}")s3_output =f"s3://{bucket}/{prefix}/output"print(f"training artifacts output location: {s3_output}")# generating the session.s3_input() format for fit() accepted by the sdktrain_data = sagemaker.inputs.TrainingInput( s3_train_data, distribution="FullyReplicated", content_type="text/csv", s3_data_type="S3Prefix", record_wrapping=None, compression=None,)valid_data = sagemaker.inputs.TrainingInput( s3_valid_data, distribution="FullyReplicated", content_type="text/csv", s3_data_type="S3Prefix", record_wrapping=None, compression=None,)testg_data = sagemaker.inputs.TrainingInput( s3_testg_data, distribution="FullyReplicated", content_type="text/csv", s3_data_type="S3Prefix", record_wrapping=None, compression=None,)
training files will be taken from: s3://learnableloopai-blog/abalone/train
validation files will be taken from: s3://learnableloopai-blog/abalone/valid
testing files will be taken from: s3://learnableloopai-blog/abalone/testg
training artifacts output location: s3://learnableloopai-blog/abalone/output
4.3 Training a Linear Learner model
First, we retrieve the image for the Linear Learner Algorithm according to the region.
Then we create an estimator from the SageMaker Python SDK using the Linear Learner container image and we setup the training parameters and hyperparameters configuration.
# # get the linear learner imageimage_uri = retrieve("linear-learner", boto3.Session().region_name, version="1")
---------------!
Endpoint: linear-learner-2021-05-21-19-45-14-793
CPU times: user 270 ms, sys: 12.6 ms, total: 283 ms
Wall time: 7min 32s
6.1 Test Inference
Now that the trained model is deployed at an endpoint that is up-and-running, we can use this endpoint for inference. To do this, we are going to configure the predictor object to parse contents of type text/csv and deserialize the reply received from the endpoint to json format.
# configure the predictor to accept to serialize csv input and parse the reponse as jsonlinear_predictor.serializer = CSVSerializer()linear_predictor.deserializer = JSONDeserializer()
We use the test file containing the records of the data that we kept to test the model prediction. Run the following cell multiple times to perform inference:
%%time# get a testing sample from the test filetest_data = [row for row inopen(FILE_TESTG, "r")]sample = random.choice(test_data).split(",")actual_age = sample[0]payload = sample[1:] # removing actual age from the samplepayload =",".join(map(str, payload))# invoke the predicor and analyise the resultresult = linear_predictor.predict(payload)# extract the prediction valueresult =round(float(result["predictions"][0]["score"]), 2)accuracy =str(round(100- ((abs(float(result) -float(actual_age)) /float(actual_age)) *100), 2))print(f"Actual age: {actual_age}\nPrediction: {result}\nAccuracy: {accuracy}")
Actual age: 9
Prediction: 8.83
Accuracy: 98.11
CPU times: user 4.66 ms, sys: 0 ns, total: 4.66 ms
Wall time: 19.6 ms
6.2 Delete the Endpoint
Having an endpoint running will incur some costs. Therefore as a clean-up job, we should delete the endpoint.